INTRODUCTION
Language Sample Analysis (LSA) has a long tradition in research focused on language development as well as in research and clinical practice within the speech-language pathology discipline where the focus is on the assessment of developmental language disorders in children [1], [2]. The advantages of LSA can be summarized in the fact that it enables both researchers and clinicians to obtain more realistic insights into childrenŌĆÖs functional language. This is particularly true for preschool children, because younger have greater difficulty in presenting their actual language abilities during formal testing (e.g., due to test-taking unfamiliarity or motivational reasons). This ecological validity paired with the breadth of data elicited - covering language aspects such as grammar, vocabulary, phonology, narrative, pragmatic and communicative abilities - enhances its value. For example, Ebert and Pham ([3], p.43) stated: ŌĆ£The language sample can provide information on multiple language dimensions at the micro- and macrostructural levels.ŌĆØ Eisenberg et al ([4], p.633). Used the clinical perspective to highlight that: ŌĆ£A diagnosis of language impairment in young children may be more accurately accomplished through the use of quantitative LSA measures than through standardized testsŌĆØ. This perspective is supported by researchers [5], [6] and clinicians [7], [5] who also argued that LSA of spontaneous language samples can be regarded as a culturally unbiased method that can help identify language impairment in multilingual children with higher accuracy than language tests. LSA has even been praised as the ŌĆ£gold standard procedureŌĆØ when assessing the expressive language skills of both mono- and multilingual children ([8], p. 339) thus deeming it as useful for ŌĆ£complex language and cultural environmentsŌĆØ ([9], p.499). Researchers are constantly attempting to advance the reliability, validity and practicability of LSA by producing a variety of different concepts, approaches and (digital) tools [10], and by making LSA applicable to diverse contexts and populations - thereby strengthening its usefulness as a method. However, LSA is still not routinely implemented in clinical practice [11].
The current study therefore attempts to conduct a scoping review of the current evidence on the methodology of LSA in order to investigate if that might hold a clue as to why it is not frequently implemented in clinical practice despite its obvious value and advantages. Particular attention is paid to language sampling contexts that represent spontaneous, non-imitative language (e.g., conversational or play-based) as these are regarded as being closest to everyday communication and do not tap into other cognitive abilities (e.g., story retelling/memory). Therefore, this review only focusses on studies that present original or archival data on the methodology of LSA guided by its chronological components, namely determining (i.e., size in number of words/utterances or length in minutes) collecting, transcribing, coding and analyzing the language sample. Unique questions are tied to each of these five components, but to our knowledge this is the first review on LSA methodology that attempts to provide an overview of all five components. Thereby, this review can map out the entire process of LSA, compare efforts across components, identify research gaps and provide a holistic procedural view. Thus we will refer to these five components in the methodology, results and discussion sections.
Determining language sample length/size
The discourse on this component revolves around using the shortest possible sample length that will yield reliable data (i.e., contain the targeted information to render a representative view of the childŌĆÖs language abilities). Sample length/size effects are calculated in the literature for different age groups [12], different language status (typical developing vs. developmental language disorders) [13], different sampling contexts [14] and different LSA measures [15].
Collecting
Research in this component aims to identify the specific contexts that elicit the most talking, with the most complex language repertoire possible to best reflect the childŌĆÖs functional communicative abilities. Advantages and limitations of specific elicitation conditions are discussed (e.g., narrative, play-based, expository), often with reference to their degree of structuredness [4]. Several individual variables have been considered when evaluating elicitation contexts, all of which may influence the collected sample. Among these are broader aspects such as setting (e.g., laboratory vs. home) [16], age and language status of the children [17], [18], communication partners [19], [20], as well as aspects regarding the communicative elicitation itself [21].
Transcribing
Coding
Research related to the coding component is similar to that discussed in the transcribing component: the amount of time it takes to code samples [26] and coding accuracy/reliability [27]. Similarly, coding conventions have been developed [24], [25], such as those focused on specific LSA units (e.g., utterance units: [28]), measures (e.g., mean length of utterance [MLU]; [10]), or those focused on the level of detail (e.g., MLU in words, syllables or morphemes: [29], [30]).
Analyzing
Research on this core component of the LSA process constantly seeks to improve the methodsŌĆÖ outcome in multiple language domains such as grammar, vocabulary and verbal fluency. New measures have been developed that share different levels of commonality, ranging from single-score general outcome measures to measures assessing separate components within a skill area in a more complex and detailed way [31]. Existing measures have been evaluated in terms of their diagnostic value for different languages [3] and also for mono- and bilingual children [32ŌĆō35].
Research on how technology could assist and advance this component, has also grown in the 21st century. Several hardware and software tools have been developed to support the analysis of language samples, such as Computerized Language Analysis (CLAN) [24], Systematic Analysis of Language Transcripts (SALT) [25], Computerized Profiling (CP) [36], and Language Environment Analysis (LENA) [37]. Recent advances in machine learning and natural language processing have accelerated the research in this field even further [38].
As we approach this scoping review focused on the methodology of LSA, we aim to identify aspects that researchers have been addressing within these five components during the last decade. These are seen as direct answers to some of the most pressing needs for improving the validity, reliability and efficiency of LSA, thus promoting its applicability in research and clinical practice. In order to contribute and advance the field we will highlight areas that are well researched while revealing areas that are under researched and therefore require attention in the future. As such, the review will inform researchers and clinicians who are interested in LSA on which of these components consensus has been reached in terms of methodology, and where controversy still remains. Furthermore the review will specifically elaborate on current trends in LSA methodology with regard to automation as it is an important aspect of future development and might impact LSA fundamentally if expanded to all its components. The objectives of this scoping review are thus:
To examine and synthesize the current published research related to the five components of the LSA process: determining the length/size of the sample (I), collecting the sample (II), transcribing the sample (III), coding (IV) and analyzing the sample (V).
To analyze the contributions of recent research (2010ŌĆō2020) regarding the methodological considerations related to these components of the LSA process.
To draw conclusions from these findings in terms of future research directions and needs for methodological advancement overarching the LSA process as a whole with a special focus on automation.
METHODS
Search protocol
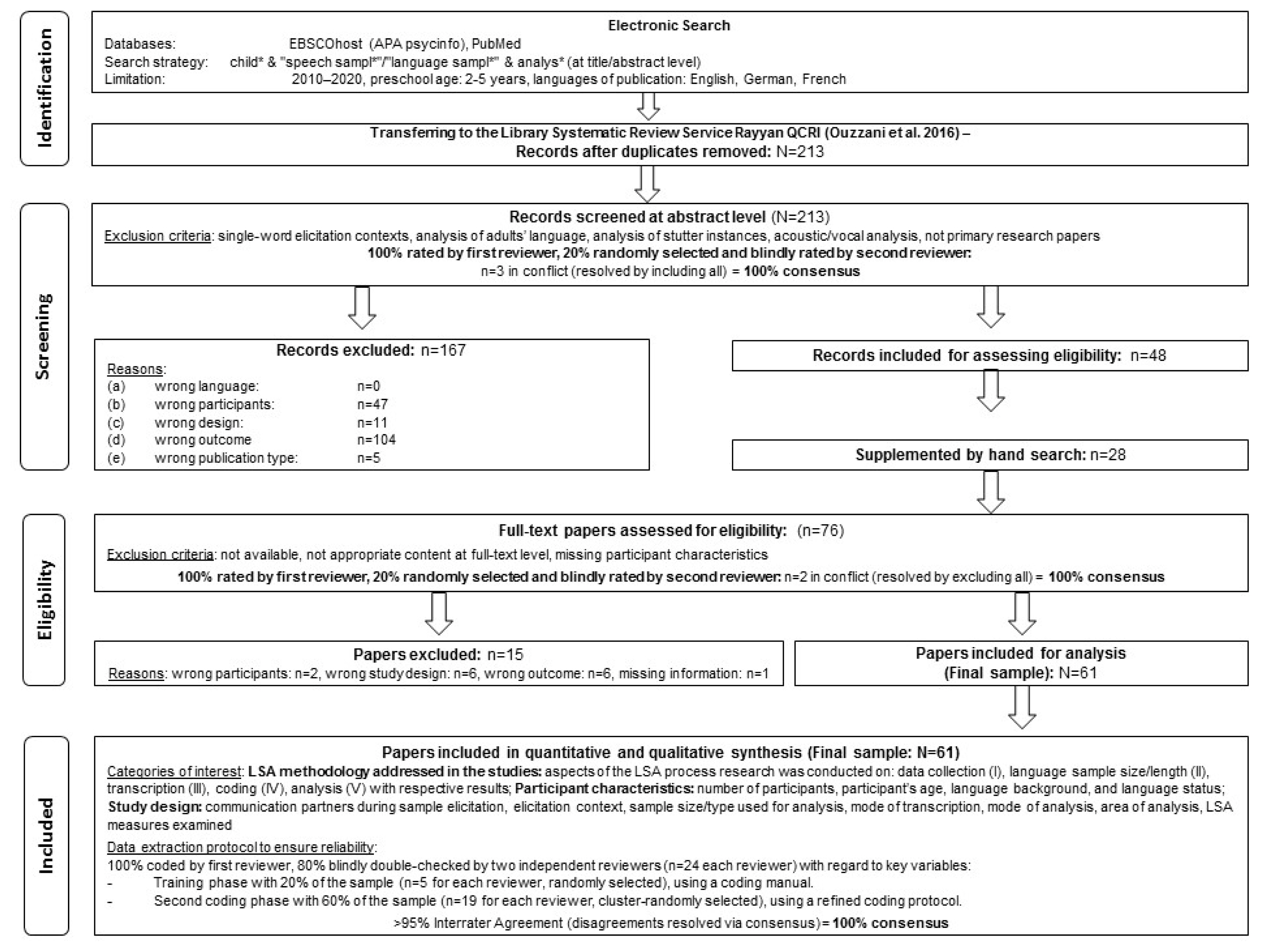
This scoping review is reported in accordance with the PRISMA-ScR statement (Tricco et al., 2018) as shown in Figure 1. In order to identify scientific publications that focus on recent research on LSA methodology a systematic search of the literature was conducted. It commenced with an electronic database search of the online research platforms EBSCOhost (APA psycinfo) and PubMed as they cover the databases most likely to index studies on LSA. Our search terms were generated on the basis of 100% consensus within the team after a preliminary review of the literature. Search terms using Boolean operators at either title or abstract level (with truncation) included the following: (AB child* AND AB ŌĆ£speech sampl*ŌĆØ AND AB analys*) OR (AB child* AND AB ŌĆ£language sampl*ŌĆØ AND AB analys*), respectively (child* [Title/Abstract] AND speech sampl* [Title/Abstract] AND analys* [Title/Abstract]) OR (child* [Title/Abstract] AND language sampl* [Title/Abstract] AND analys* [Title/Abstract]) for PubMed (finding all search terms as search mode). The electronic search was further supplemented by hand searching. After deleting duplicates, 213 papers remained for screening at the abstract level.
For the screening phase, inclusion and exclusion criteria were employed. We limited the publication date of the included papers to the last decade (2010ŌĆō2020), to summarize recent research on the topic. The number of relevant publications in the databases showed a clear increase from 2010 onward, reflecting a growing interest. In addition, we only included studies that focused on preschool children (mean age of the participants Ōēż72 months) as LSA methodology differs considerably across age groups, with regards to elicitation contexts and measures. However, the review did not set any exclusion criteria regarding language status and included children with typical development, developmental language disorders, and those at risk for developmental language disorders. For participant descriptions, we relied on how the disorders were described in the original studies. Furthermore, we included both mono- and multilingual children. Irrelevant studies were excluded at title and abstract level in the first round conducted by two reviewers. We defined exclusion criteria as: (a) studies not published in English, German or French (i.e., wrong language studies); (b) studies analyzing the language only of school-age children, adolescents or adults, studies analyzing LSA methodology in children with language disorders associated with biomedical conditions (i.e., wrong participant studies); (c) studies using single-word elicitation contexts or samples which cannot be seen as spontaneous, non-imitative language (including story retelling) (i.e., wrong design studies); (d) studies that employed LSA as a method, but that only presented results on the speech and language development of their participants and not on the LSA methodology itself, as well as studies concerned with acoustic, vocal or disfluency analyses, or studies only considering distributional measures of language analysis using LENA technology (which have already been reviewed by Ganek and Eriks-Brophy [40]) (i.e., wrong outcome studies); (e) studies that are background papers and that did not present original data on LSA methodology or that are not peer-reviewed such as grey literature (e.g., conference abstracts, presentations, tutorials, proceedings, government publications, reports, dissertations/theses, patents and policy documents) (i.e., wrong publication-type studies).
Of the 213 papers included in the screening phase, a total of 77.5% (n=165) were excluded by mutual agreement between the two reviewers. The majority of these studies (n=104) were excluded because they had the wrong outcome, mostly employing LSA as a method in their research without focusing on the methodology of LSA itself. In total, 48 papers from the electronic search plus 28 papers from the hand search remained after the screening phase for determining eligibility (n=76).
During the eligibility phase, all 76 papers were reviewed at full-text level. 100% were reviewed for inclusion/exclusion by the first reviewer and 20% randomly selected and blindly rated by a second reviewer. After full-text reading, 16.4% (n=15) of studies were excluded. The final sample of this review thus comprised 61 included papers.
Data extraction
In the final phase, data extraction was conducted on all 61 included papers using a custom-designed data extraction protocol. Variables focused on participant characteristics, study design as well as the five components of the LSA process. All information and aggregated data were extracted from the included papers. The collected information was then tabulated and analyzed both quantitatively and qualitatively at a descriptive level, noting patterns in methodology and gaps in knowledge. To better structure the amount of research in the analysis component (V) we differentiate between studies that focused on monolingual mainstream English-speaking children and children who speak any other languages/dialects (including multilingual children). Additionally, we also divided our data related to this component into several subcategories due to the variety of topics covered in the papers. First, (a) we summarize the development of new LSA measures (previously unpublished measures or measure modifications) or the adaptation of existing measures. Second, (b) we explore the value of LSA measures by describing the diagnostic value, growth value and value in terms of usefulness. Diagnostic value refers to the identification of children with (or at risk for) developmental language disorders, according to LSA measures (only studies computing statistics such as classification accuracy, ROCŌĆōanalysis, sensitivity/specificity, or positive/negative likelihood ratio [LR+/ŌłÆ]). Growth value refers either to determining the stage or overall level of language development or change following intervention via LSA measures. Value in terms of usefulness refers to the exploration of feasibility, reliability and validity. Third (c) we synthesize data on automated LSA, by describing studies that compare digital vs. manual analysis, and examining the reliability of software support.
Reliability
A data extraction protocol, based on the following interrater ratios, was used: 100% coded by the second author, 80% double-blindly checked independently by the third and fourth authors (n=24 for each reviewer). A coding manual was used for categorizing variables in terms of LSA methodology. There was a training phase with 20% of papers (n=5) randomly selected for each of the three reviewers, using the coding manual. Training enhanced inter-rater reliability. The coding phase involved 60% of the sample (n=19) randomly selected for each of the reviewers, using a refined coding protocol. Interrater agreement of >95% could be reached for the final data extraction. Disagreements were resolved via consensus discussions. The PRISMA chart in Figure 1 summarizes all these steps.
RESULTS
Descriptive results regarding participant characteristics and study design of the 61papers included as the final sample are reported in supplement A. In the results section, we present summaries of the studiesŌĆÖ results arranged according to the components of the LSA process, as per the aims of the review: determining the language sample length/size (I), collecting (II), transcribing (III), coding (IV) and analyzing (V) (see supplement B for the categorization criteria). Table 1 provides an overview of these components targeted in the included studies.
Determining the length or size/length of the language sample (I) is described in 17 of the 61 studies (28%); collecting the sample (II) in 11 studies (18%); transcribing (III) in two studies (3%); coding (IV) in six studies (10%), and analyzing the sample (V) in 48 studies (79%), making it the most frequently addressed component.
Determining the length/size of the language sample
Studies focused on the length/size of the language sample vary greatly e.g., according to the unit of comparison that is used (e.g., utterances, minutes, tokens, number of elicitation materials), the measures that are calculated (e.g., MLU, D, TTR, FVMC, TAPS, TNW, TDW), the sample sizes that are used in the comparisons (e.g., > 200 vs. 100 utterances, 100 vs. 50/25/12 utterances), the position of the subsamples (e.g., beginning/middle/end of the transcript, transcript split into two halves, even/uneven number of tokens), and the statistical method used to assess measurement reliability (e.g., relative vs. absolute reliability). This diversity complicates clustering and synthesis of results on this component of the LSA process. Nevertheless, seven studies reported a clinically relevant effect of sample size/length on the measures computed in their studies [41ŌĆō47]. This effect was reported, for example in study [41], with regard to decreased diagnostic accuracy when comparing Finite Verb Morphology Composite (FVMC), and Tense and Agreement Productivity Score (TAPS) in samples of 50 utterances vs. samples of 100 utterance, and in study [42] in terms of the lower reliability of two global lexical measures (i.e., total number of words TNW/m and number of different words NDW/m) as well as mean length of utterances in morphemes (MLUm) when comparing 3- and 7-minute consecutive segments to 10-minute consecutive segments or to the whole 22-minute samples. In contrast, five studies [13], [48ŌĆō51] did not find sample size to have a clinically relevant effect. The shortest reliable sample lengths reported in these five studies were: MLUm in several 10 and 20-utterance subsamples of total samples comprising 100ŌĆō150 utterances in children with developmental language disorder [13] as well as two of three SUGAR metrics (MLUSUGAR, words per sentence [WPS], clauses per sentence [CPS]) with no statistically significant differences between the two conditions (i.e., 25 vs. 50 utterances) for MLUSUGAR or WPS in typically developing children [51].
A third group of studies specified their findings depending on the type of LSA measure with mixed results [53], [54], [55], [56]. Study [53] reported a greater influence of language sample length mostly on additive measures of diversity and productivity, such as number of different words (NDW), type/token ratio (TTR), tense marker total (TMT), and productivity score (PS). MLU or lexical diversity measured by d, for example, were less affected [53ŌĆō55].
Collecting a language sample
Results regarding this component focus on advantages and limitations of specific elicitation conditions. Four subsections related to this component are described.
Effect of different elicitation contexts
Five studies compared different elicitation contexts [4], [56], [18], [57], [58] and all highlight the impact of the elicitation context on LSA. Both study [4] and study [56], the latter for bilingual SpanishŌĆōEnglish-speaking children, reported a significant influence of the elicitation context on the majority of the LSA measures included in their studies (DSS sentence point score, DSS passŌĆōfail decisions, D for lexical diversity in typically developing children, MLUw, and sentence complexity). No significant effect was found in the DSS overall score [4], or in the lexical diversity (D in children with developmental language disorders) or grammatical errors per communication unit [56]. In both studies, the children tended to score higher in the unstructured elicitation contexts (the former: play vs. picture description; the latter: story telling vs. retelling). This was especially true the younger the sampled children were [18]. Furthermore, when examining mean length of utterance in words (MLUw) based on transcribed consecutive excerpts of LENA audio files (CEAFs: 50 utterances or 30 min) from monolingual and bilingual (English/Spanish) children, the MLUw in both groups of children were lower than expected on the published norms on traditional LSA procedures [68].
Effect of the linguistic content during elicitation
The three studies [53], [59], [60] concerned with the linguistic content of the elicitation (e.g., topics, question types), found contrasting results regarding its influence. Study [53] reported similar performance on LSA measures despite changes in topic (school-related activities vs. non-school activities), while study [60] found an effect of topic familiarity in their discourse tasks (explanation of home routine vs. function of a magnet), with children showing on average better performance in the LSA measures based on the familiar task. Study [59] reported that different types of questions (external state, procedural action, epistemic, causal) provided evidence of obligatory strength for the production of full-sentence responses. When the focus was narrowed to multi-verb (complex) sentences, open-ended external state questions (e.g., ŌĆ£WhatŌĆÖs happening?ŌĆØ) elicited significantly more language than any other type of question.
Amount of time to collect samples
Only two studies [10], [26] reported on the amount of time to collect samples. Both indicated that on average, five to six minutes was needed to collect 50 utterance samples in conversational discourse using a standard language sampling protocol designed to promote production of complex language from children of different ages (36ŌĆō95 months) and with different language status (typically developing vs. developmental language disordered). The average time did not differ according to age or language status.
Feasibility of samples collected via video
Only one study [61] investigated the feasibility, reliability and validity of language samples collected via telepractice. It reported no significant differences between the in-person and the video (telepractice) sample in terms of mean transcript reliability or the LSA measures calculated (percent intelligible child speech, MLU, NDW, TTR, language errors and omissions).
Transcribing
The two studies that addressed this component [10] and [26] both focused on the amount of time taken to transcribe language samples. Both studies showed that the mean time required to orthographically transcribe 50 intelligible child utterances and analyze a language sample for the four metrics they included (MLUSUGAR, WPS, TNW, CPS) was 15.3 minutes. The amount of time did not differ markedly across age groups (36ŌĆō95 months) or language status, although the children with developmental language disorder produced more unintelligible words.
Coding
Six studies included three subsections related to the coding component, namely:
Specification of coding with respect to individual LSA measures
Four of the six studies [62], [15], [45], [63] focused on LSA measures, mainly MLU. Study [62] presented a revised version of the index of productive syntax (IPSyn-R), which provides more detailed and less ambiguous guidelines for coding. Study [15] showed that the MLUw and MLUm in English and French correlated almost perfectly. MLUw and MLUm also correlated in a detailed analysis of two English-speaking childrenŌĆÖs language trajectory (one typically developing, the other with developmental language disorder) despite some significant differences, thus suggesting that MLUw and MLUm reflect two separate types of linguistic development (lexicon vs. morphosyntactic development), which cannot substitute one another [65]. Acceptable agreement was found in Russian between MLUs and MLUm with researchers concluding that MLU in syllables (with minor adjustments) is the easier-to-code alternative [45].
Identification of utterance boundaries
Only one study [27] investigated the identification of utterance boundaries by different listeners by exploring whether adult listeners could identify utterance boundaries in childrenŌĆÖs natural spontaneous speech. Results showed significant differences in the number of utterances identified and in the utterance boundaries which were influenced by different speech characteristics, such as the length and grammatical complexity of the response, turns, pauses, sentence/clause boundaries, response turn shifts and a number of convergent features.
Real-time coding
Only one study [27] attempted to investigate real-time coding by rating 1-minute timed samples in a binary manner as either ŌĆ£acceptableŌĆØ (structurally complete, grammatically correct, and contextually appropriate without syntactic or semantic errors) or as ŌĆ£incorrectŌĆØ. This coding was done in real time and then compared with traditional 100-utterance samples. Results revealed significant correlations in linguistic data across both forms of language sampling.
Analyzing
The component of LSA that deals with analyzing the data was divided into three subsections as described earlier: a) development of new LSA measures, b) value of LSA measures and c) automated LSA (c). Over 60 different measures were analyzed in the sampled studies (see supplement A). A total of 27 studies (56%) concentrated on monolingual English-speaking children. Of these eight introduced new LSA measures [64], [65], [49], [54], [66], [67], [19], [47], 17 focused on the value of LSA measures (use, growth and diagnostic value) [68], [49], [69], [70], [71], [41], [72], [73], [74], [52], [9], [75], [10], [26], [60], [51], [76], and four on the use of automated LSA [77ŌĆō80]. A further 21 studies (44%) focused on other children (i.e., non-monolingual mainstream English-speaking children) as shown in Table 1. Of these studies, seven were concerned with new LSA measures or measure adaptation [81], [82], [43], [57], [45], [83], [84], 17 with the value of LSA measures (use, growth, and diagnostic value) [85], [56], [86], [43], [9], [60], [87], [88], [89], [57], [90], [55], [15], [45], [91], [92], [84], and two with automated LSA [82], [90].
Development of new measures
The previously unpublished measures for monolingual mainstream English-speaking children mostly target grammar. For example, the authors of study [65] aimed to develop normative expectations for the level of grammatical accuracy in 3-year-old children, by first introducing a measure of grammaticality, percentage of grammatical utterances including fragments (PGU), defined as C-units containing one or more errors in eliciting picture descriptions with four questions per picture. In Study [67] an approach is proposed for assessing sentence diversity in young children (30 and 36 months) by measuring the unique combinations of grammatical subjects and lexical verbs (USV). To be identified as a USV, a childŌĆÖs sentence is required to include an explicit noun or pronoun in the subject noun phrase (NP) position, to include a lexical verb, and to reflect a sufficiently different subject-verb combination.
Measures were also described for other languages and dialects. For example, for a Persian [83] and a Japanese [43] version of the DSS, a French version of the Language Assessment, Remediation and Screening Procedure (LARSP) [82] and a Czech version for analyzing MLU and mean number of words from certain grammatical categories per utterance [57]. Adaptations included either evaluating the appropriateness of the original English items, possible selection of language-specific equivalents of the original items, or gathering and grouping a completely new set of items based purely on observations of the childŌĆÖs development in the target language. Three additional studies introduced new sets of measures [44], [83], [84]. For example, the authors of study [83] expanded their own previously identified competencies for children speaking African American English to a minimal competence core of morphosyntax (MCC-MS) including MLUm, measures of sentence completeness, sentence clausal complexity, sentence variation (lexical, phrasal, clausal level), and sentence ellipsis.
Value of LSA measures
Table 1 shows that the studies captured different aspects of value (e.g., diagnostic, growth or use value) of existing LSA, with 17 studies each focusing on monolingual children and other children (i.e., non-monolingual English-speaking).
Results on diagnostic value regarding classification accuracy are summarized in Table 2. Overall diagnostic accuracy of the examined LSA measures consistently reached at least an acceptable level of >80% in almost all studies including monolingual mainstream English-speaking children. Diagnostic value in studies including other than monolingual mainstream English-speaking children was mixed, with three of the five studies reporting metrics not reaching adequate levels [9], [55], [92].
Study [69] and [52] focused on growth value by evaluating change following intervention, both in monolingual mainstream English-speaking children. Study [69] compared two general LSA measures (MLU, TTR) and two intervention-specific measures (percent accuracy, TAPS of the treated morpheme) and concluded that the measures more attuned to the intervention target are most appropriate for grammatical outcome measures from LSA. Study [52] showed that three measures (FVMC, TMT, Productivity Score), all provide unique and relevant information on language growth during intervention. The ability to detect developmental growth was also evaluated for DSS in Japanese [43], MLU for Portuguese [89], several vocabulary measures for Mandarin-Chinese [84] as well as for children in different age groups (e.g., young children: [70], [72], and older children: [10]) or children with different language status (e.g., typical language development: [75], and various language abilities or developmental language disorder: [88], [15]). Most studies (irrespective of their focus on monolingual or other children) reported a correlation between their respective LSA measures and age (vocabulary: [70]; TAP: [72]; MLUSUGAR: [10]; DSS Japanese version: [43]; TAP and TMT: [87]; MLUm and NDW: [88]; MLUw: [89]; TNW, NDW, MLU and morphological diversity: [15]; average number of unique grammatical forms (AvUniqF): [45]; and vocD: [84]). However, some measures did not correlate with age or predict age in non-monolingual mainstream English-speaking children, e.g., MLU [9], T/A accuracy [87], NDW and TTR [84] and were worse in demonstrating growth in older children (e.g., MLU for Russian children older than 3;0 years [46].
In evaluating the validity, feasibility and applicability (use value) of LSA, measures were either correlated with standardized assessments, or with other LSA measures; examined for their ability to show group differences in children with various language abilities; or their general appropriateness for other than monolingual mainstream English-speaking children. Two studies addressing the latter aimed to examine whether measures were independent of English dialect or language use ([91]: IPSyn, MLUm, NDW for English/Jamaican Creole bilingual children), English exposure ([9]: MLU, D, IPSyn for English/Chinese bilingual children), or maternal education ([9], [91]), both reporting no effect on the listed possible influences. Several studies reported significant correlations (of various value) between LSA measures and standardized assessment of general language skills ([74], [88], [89]), grammar ([49], [10], [57]), or vocabulary ([70], [57]). Some authors pointed out that although LSA measures are correlated with standardized assessment, the often low numeric values indicate that language sampling measures and standardized assessment tap into relatively different aspects of the same underlying abilities (e.g., expressive language) [88]. Correlation of LSA measures within the same linguistic area were often strong in the published studies: in the Japanese DSS version and MLUm [43], in MCC-MS and IPSyn in AAE children [90], in MLUm and AvUniqF in Russian [44]. Nevertheless, some authors reported mixed results or low correlation between LSA measures mostly including other than monolingual mainstream English-speaking children (e.g., T/A accuracy, TAP, TMT, MLU, NDW) for Spanish/English bilingual children [89] as well as composite discourse score for English/various languages speaking children [60]. Two studies calculated cross-linguistic correlations to specify connection between measures for bilingual language contexts with positive [91] and mixed results [85].
Automated LSA
Four of the six studies that used automated LSA focused on monolingual mainstream English-speaking children with one focusing on French [82] and one focusing on dialects (e.g., African American English) [90]. IPSyn was the most targeted language measure in five studies [62], [78], [79], [80], [90]. Different software approaches to automatically derive IPSyn scores were proposed, which either involved encoding IPSyn target structures in a language-specific inventory as complex patterns over parse trees [62], or were fully-data driven and used only language-independent feature templates applied to syntactic dependency trees [78]. Results and conclusions derived from studies on the accuracy of machine scoring differ, ranging those that report on acceptable reliability when compared to manual scoring (i.e., a mean point-to-point agreement of around 95%, e.g., IPSyn: [79], [91]) and the French version of the LARSP [82], to those studies that still recommend caution in the clinical application of automated LSA, with point-to-point agreement below 85% [62], [80].
DISCUSSION
The purpose of this review was to collate research produced in the past decade on five components of the LSA process, namely determining the length/size of the sample (I), collecting (II), transcribing (III), coding (IV), and analyzing (V) the language sample with the aim of informing researchers and clinicians about recent methodological advancements and to identify future research needs and potential areas for improvement of LSA methodology. In this discussion we firstly address each of the components separately and reconnect it to the current state of the research evidence outlined in the introduction. Thereafter we identify topics overarching all aspects of the LSA process, and focus on the possibilities of technological support of LSA in the future.
The five components of LSA
Determining the size/length of the language sample (Component I) is a source of variability in LSA. Measures are often calculated as a proportion of the total transcript, or as means, or by calculating the frequency of specific linguistic structures in spontaneous oral language. Therefore, these measures are potentially influenced by the amount of text analyzed. The results in this review illustrate that general consensus on the prerequisite sample size/length in LSA may not be achievable, but that it might be more appropriate to be specified for different types of measures. Evidence is growing that some measures, such as MLU, may be less influenced by sample length than measures that evaluate the linguistic content of the sample in more detail [52]. Nevertheless, the size/length of the language sample is an aspect researchers and clinicians have to be cognizant of when employing LSA as a method.
In terms of collecting the language sample (Component II), this review expanded the field by highlighting the effect of elicitation contexts on specific LSA measures, the effect of the language during elicitation (topic, question type), as well as the interaction between these two constructs. This evidence does not resolve the structured vs. unstructured controversy but rather specifies the matching of elicitation contexts and questions asked during elicitation to specific target language/structures aimed to elicit from children during language sampling. The following picture arises: On the one hand preschool children tend to produce longer and more complex sentences and even score better on certain LSA measures (e.g., DSS) if the elicitation context is less structured [4], [56], [18]. This phenomenon is even more noticeable in younger preschool children [18]. On the other hand, the question type that elicits the most complex sentence structures (external state questions), occurred more frequently in the higher structured activities (e.g., barrier games and storytelling) [59]. Therefore, including open-ended ŌĆ£What happened?ŌĆØ type questions into play-based elicitation contexts, might be a way to combine both advantages.
Transcribing the sample (Component III) focused on the amount of time needed to transcribe child language samples, and was only described in two of the included 61 papers, highlighting a paucity of research. Results offer a perspective of improved efficiency of LSA regarding clinical implementation [10], [26]. Furthermore, the singular focus on this aspect related to transcription might be interpreted as a general indicator of satisfaction with existing transcription conventions (e.g., SALT or CLAN software).
However, in contrast to the transcribing component where there appears to be consensus on the procedures and rules, the same is not true for coding (Component IV). The results related to coding emphasized the continuing challenge of coding phenomena of spoken language, such as utterances or specific LSA measures (e.g., IPSyn-R), and the high variability of coding specific measures across languages (e.g., MLU). This component of the LSA process is of core importance for the reliability of LSA, because it addresses how basic measures such as MLU are calculated. The results presented in this review illustrate that final consensus related to coding is not reached yet in terms of how to segment utterances in either English, or across other languages when attempting to do cross-linguistic comparisons. In coding it becomes most obvious that spoken language differs from written language and although the text is being analyzed in LSA (i.e., transcribed recordings), the ultimate aim is to evaluate the oral language (spoken language) by means of the written sample. Hence, strategies to enhance and optimize this component should be considered and prioritized. Additionally, researchers and clinicians should be explicit in reporting how they coded their sample and/or specific LSA measures in order to allow comparison or norm use.
The results of this review regarding analysis (Component V) expand the breadth and depth of LSA by developing measures for specific purposes, focusing mainly on grammar. In addition, LSA measures are increasingly adapted to target populations other than monolingual mainstream English-speaking children emphasizing the specificity of these populations when utilizing LSA just as in formal assessment with language tests. All these efforts extend the applicability of LSA for example to younger children [65], [67] or to languages other than English [81], [82]. It also attempts to improve the applicability of LSA by refining the guidelines [62] and by developing alternative measures [10]. This review also presented further evidence on the predictive and discriminant validity of LSA measures in several languages/dialects, thereby strengthening the general value of LSA without avoiding its limitations such as demonstrating its growth value after intervention [69] or its challenges such as sampling bias [47]. Results on diagnostic accuracy of LSA measures calculated from spontaneous language samples for preschool children are promising and are not lagging behind those of standardized language tests [93] confirming the utility of LSA for clinical practice. Finally, the two approaches in machine scoring of LSA measures were shown: on the one hand those that continue to use traditional language-specific approaches of computational linguistics [62], and on the other hand those that have adopted recent approaches of purely data-driven potentially language-unspecific machine learning approaches [68]. Improvement in this area is closely related to general advancements in machine learning and to the associated paradigm change from rule-based to data-based applications in automated speech recognition and processing [94]. A fully automated LSA process from transcription to coding and linguistic analysis of the transcript is not offered by any of the existing software or tools yet. Controversy arises in this field on how to compare machine and manual scoring [80].
The overarching topic of automation
In this section we focus on the possibilities and requirements of technological advancement in supporting LSA. Other needs that can be clearly derived from the results of this review as well, such as an increase of research on LSA methodology regarding multilingual preschool children (almost 90% of the studies in this review focused on monolingual mainstream English-speaking children or monolingual children speaking other languages or dialects) or the establishment of guidelines tailoring LSA to specific purposes, age groups, language status and language/dialect backgrounds to inform best practice are not addressed in detail (but see e.g., [5]).
Technological support (hardware and software) can be associated to every one of the five components of the LSA process that framed this review, but the central most impacting development in the future will be automatic speech recognition applications that are able to process spontaneous child language leading to automated transcription and coding. Observing the distributed areas of interest in the studies included in this review (Table 1), these parts of the LSA process have yielded the least research in the last decade. Future expansion of automation might change this. Currently, software support is only available for the last component ŌĆō analyzing the language samples (with the exception of CLAN offering some features for coding) [24], [25]. Tied to the expansion of transcribing and coding automation is the ability to record truly spontaneous language samples in natural settings and analyze their linguistic content. With software support the two most time-consuming and resource intensive steps of the LSA process determining the sample size will become unnecessary. What has to be kept in mind however, is that spontaneous conversation produces a different type of data than samples elicited under structured conditions [57]. This will lead to the development of new LSA measures and require the establishment of specific norms for parameters derived from every-day communication [58]. In the still mostly ŌĆ£manualŌĆØ present, the following dilemma arises: The more natural (unstructured) the elicitation context the more representative the sampled language, but also the longer it takes to collect (and then transcribe and code) a desired amount of language to calculate LSA measures, because the frequency of targeted structures (e.g., complex language) may be much lower in natural communication [65], [46], [47]. Automatic transcription (orthographic and possibly even phonetic) would reduce the time-consuming aspect of LSA substantially, improve its efficiency and therefore avoid this dilemma. Additionally, automated transcription and coding would strengthen the applicability of LSA and if long-dated, it could even be expanded to fully develop its potential in providing insights into multilingual language learning and how it is used within communicative interaction in natural settings, including children and their caregivers, peers, teachers and other communication partners. In terms of advancements related to the coding and analyzing components of LSA, machine learning opens new possibilities as not only the text data but also audio data (and possibly even video data) will become accessible for exploration. This might lead to an even further expanded applicability of using speech and language samples for diagnostic and research purposes combining parameters derived from transcripts and audio/video recordings [95]. At present we only have tools relying either on the (manually transcribed) text data (CLAN: [24], SALT [25]) or the processed audio data (LENA: [36]). Finally, a fully automated LSA process might enable the evaluation of SLP intervention outcome according to change in communicative participation in everyday situations as ultimately aspired by the conceptual framework of the International Classification of Functioning, Disability, and Health, (ICF) proposed by the World Health Organization (WHO) [96]. To develop these tools, interdisciplinary collaboration (e.g., engineers, SLPs, computer linguists) is necessary. The contribution of SLP is firstly, to inform machine learning models with knowledge on typical and atypical language development on all linguistic levels. Secondly to design and supervise the collection of appropriate data for model training, because as has been stated earlier the shift in machine-learning development to data-based, so called ŌĆ£deep learningŌĆØ, requires large amount of adequate data to train and test the applications for the intended purpose. Lastly, to address ethical implications of automation relevant to the context of assessing the developing communicative abilities of children for clinical and research purposes.
Limitations
Some limitations of this current study must be considered. The first deals with our search and study selection strategy. The present scoping review included only studies that were accessible via the listed databases. Due to the very specific focus of this review (research on LSA methodology) on the one hand and the broad range of topics covered by this focus on the other hand (the five targeted components of the LSA process), deciding on appropriate search terms was challenging. Not all of the studies included ŌĆ£language/speech sampleŌĆØ in their key words, but rather broad descriptors such as ŌĆ£language assessmentŌĆØ, which would have significantly enlarged the electronic search, resulting in a large number of excluded studies. Therefore, we decided to rather augment the electronic search with thorough hand searching [97]. Furthermore, we labeled picture naming, imitation of target words and story retelling as elicitation contexts which do not reflect spontaneous language close enough, resulting in the exclusion of several studies. However, it is acknowledged that this decision (especially with regard to story retelling) may not be subject to consensus among the entire scientific community, and the results of these studies might also contain information contributing to research on LSA methodology [33], [98]. The focus of this review is also only on preschool children, therefore, implications drawn might not be applicable across other age groups (i.e., school-age and adolescence). In addition, the exclusion of dissertations and theses that may have evaluated components of LSA methodology could introduce publication bias into the review. Furthermore, the generalizability of the results is negatively impacted by the fact that within some of the five LSA components building our main variables reviewed, there were only a few papers included (e.g., for the transcribing component). Overrepresentation of IPSyn studies in the section on automated LSA may be due to the fact that other studies on automated LSA had technical aims and therefore more mixed groups of participants or lacked information on participant characteristics and thus did not meet the participant inclusion criterion e.g. [99], [100]. Finally, not all studies provided information on all aspects included in the data extraction (resulting in missing data), or reported it in the same way (e.g., software use in different parts of the LSA process). Although it may limit the validity of our results, it also draws attention to the absence of guidelines in how to report the methods and results in LSA studies, limiting opportunities for conducting meta-analysis of data [101].
CONCLUSIONS
This review shares data from 61 studies on LSA methodology published between 2010 and 2020, by synthesizing existing evidence on five components of LSA: determining the sample length/size, collecting, transcribing, coding and analyzing the sample. The review highlighted the current debates in the field and described the breadth of topics covered by the extant literature that reflects the wide range of potential LSA applicability. At the same time, this variability expressed in how studies were conducted and how results were reported, makes it challenging to compare studies, to draw clinical conclusions, and to show implications for future research [102], [10], [80]. Therefore, it is recommended that future research might establish refined guidelines to optimize the potential of LSA for diverse purposes in mono- and multilingual children of different ages and language status. The greatest singular potential in future LSA advancement is seen in technological support expanding to the transcription and coding of child language data, enabling the recording of complex linguistic data in real-life contexts, thus fully redeeming the promise of ecological validity.